StepFun, the Shanghai-based AI lab, released StepAudio 2.5 Realtime. It is an end-to-end real-time speech large language model with fully customizable persona capabilities.
StepAudio 2.5 Realtime is a voice model that operates in real time. Unlike pipeline-based systems that separate speech recognition, reasoning, and synthesis into sequential steps, this is an end-to-end model. Audio goes in and audio comes out through a single unified system. The model supports Chinese and English.
It connects via a WebSocket API. The endpoint is wss://api.stepfun.com/v1/realtime using the model string step-2.5-realtime.
The Three Technical Pillars
StepFun research team describes three core architectural innovations behind the model:
1. Million-Scale Persona Data AugmentationStarting from 10,000+ high-quality natively authored personas, StepFun applied algorithmic augmentation to build a million-scale persona feature matrix. This was combined with millions of real-world conversational samples for training. The intent is generalization — specifically, stable performance on difficult, long-tail conversational topics.
Instead of manually labeling millions of persona samples, StepFun team used algorithmic expansion from a curated seed set.
2. Roleplay-Specific RLHF AlignmentA known failure mode in conversational AI is “out-of-character” (OOC) behavior — when a model drifts away from its defined persona mid-conversation. StepFun team conducted dedicated RLHF (Reinforcement Learning from Human Feedback) optimization specifically for persona consistency in roleplay scenarios. RLHF is a training technique where human preference signals are used to train a reward model, which then guides language model behavior. Applying it specifically to roleplay stability is a targeted design choice.
3. Unified Speech Understanding and GenerationStepAudio 2.5 Realtime inherits the StepAudio 2.5 TTS capabilities and deeply fuses speech understanding and generation through reinforcement learning. This enables what StepFun calls “global scene-level tonal setting” and “intra-sentence detail sculpting.” The model can set an overall emotional register for a response while adjusting finer acoustic details within individual sentences.
Paralinguistic Understanding
A technically distinct area of this model is paralinguistic perception. Paralinguistics refers to non-verbal acoustic information in speech — things like tone, speaking rate, pauses, sighs, and laughter. By analyzing these elements, the model can perceive the user’s mood and underlying intentions. For example, it can identify fatigue from a low tone or frustration from a rapid speech rate. Capturing these signals requires the model to operate on audio features rather than transcribed text alone.
StepAudio 2.5 Realtime scored 82.18 on the paralinguistic comprehension benchmark, demonstrating perception of vocal speed, emotion, age, and other acoustic features.
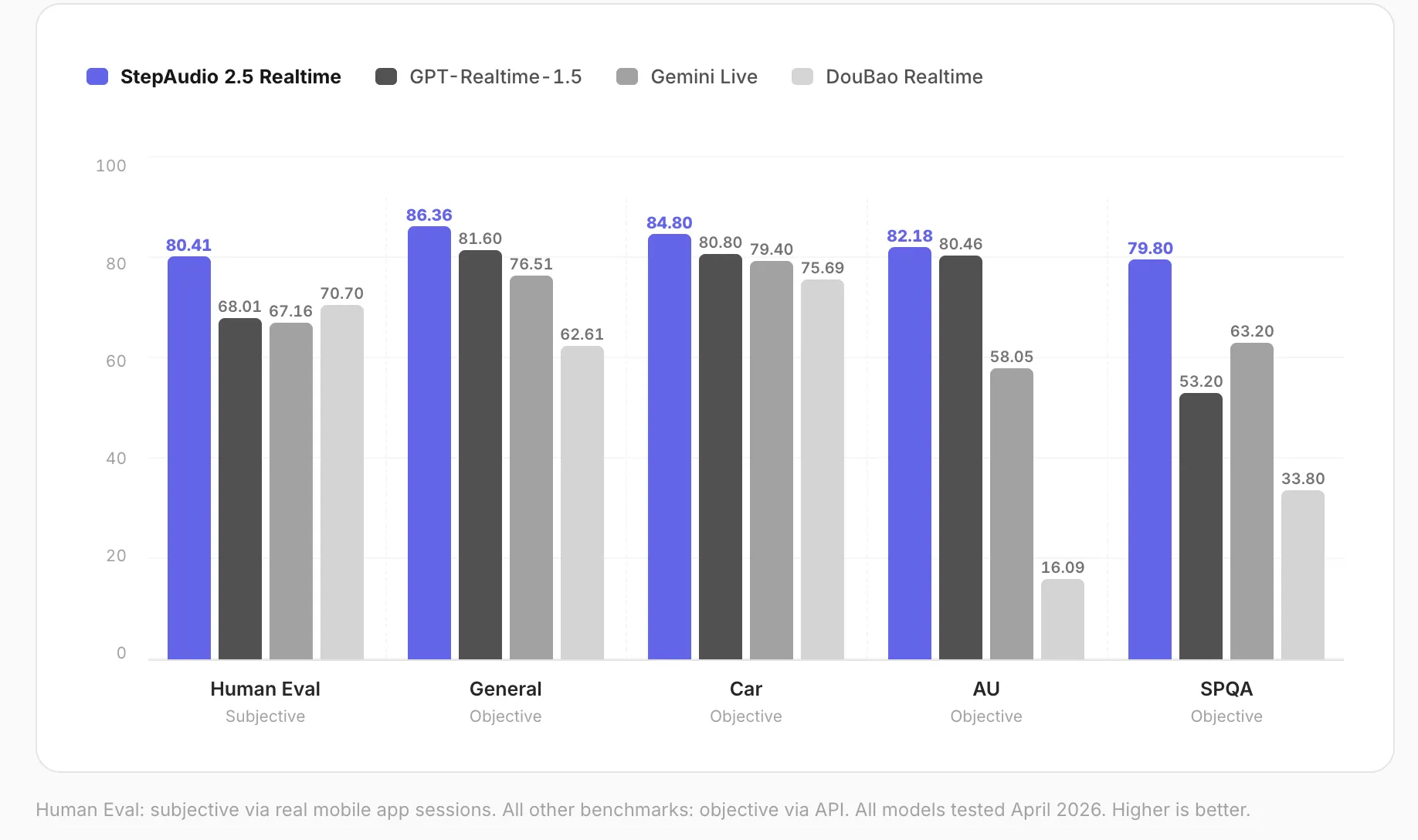
Benchmark Results
StepFun research team conducted a comprehensive suite of subjective and objective evaluations, benchmarking StepAudio 2.5 Realtime against leading real-time voice models across five dimensions.
Human evaluation is conducted through real mobile app conversations scored by human raters. The scores:
- Human evaluation (subjective): 80.41
- General dialogue (objective): 86.36
- Automotive scenario (objective): 84.80
- Spoken QA, covering 11 audio understanding tasks (objective): 79.80
- Paralinguistic comprehension (objective): 82.18
Key Takeaways
- StepAudio 2.5 Realtime is an end-to-end real-time speech LLM, released by Shanghai-based StepFun.
- It uses persona-specific RLHF and million-scale data augmentation to maintain stable character consistency.
- The model ranked first across all five benchmark dimensions, tested in April 2026.
- Paralinguistic comprehension — perceiving tone, rate, emotion from audio — is a core technical differentiator.
- API access is via WebSocket at
wss://api.stepfun.com/v1/realtimewith model stringstep-2.5-realtime.
Check out the Model Card and Demo. Also, feel free to follow us on Twitter and don’t forget to join our 150k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Need to partner with us for promoting your GitHub Repo OR Hugging Face Page OR Product Release OR Webinar etc.? Connect with us
The post StepFun Releases StepAudio 2.5 Realtime: An End-to-End Voice Model with Roleplay-Specific RLHF and Paralinguistic Comprehension appeared first on MarkTechPost.