NVIDIA Research introduced HORIZON, a hands-free agent framework for hardware design. It treats hardware design as repository-level code evolution. This research team exercises the register-transfer level (RTL) instantiation. A structured Markdown harness becomes a project pack. A self-contained agent loop then evolves an isolated git worktree. It commits a version only when an executable acceptance gate passes.
The research team reports 100% completion across every evaluated RTL benchmark suite. It also states plainly that agentic hardware design is not solved.
What is HORIZON?
Single-turn code generation has a clear limit on executable design tasks. Plausible Verilog is not enough for real hardware. Correctness depends on cycle-level behavior, reset conventions, bit widths, and simulator feedback.
HORIZON hosts each design problem as a version-controlled repository, not a one-shot prompt. The only required input is a structured Markdown harness. That harness carries four components: a goal, domain-knowledge directions, an evaluator specification, and an acceptance predicate.
A bootstrap agent compiles the harness into a project pack. The research team writes this as p = (πagent, Ep, Ap, Γp, Ωp). Those terms cover the agent policy, the executable evaluator, and the acceptance predicate. They also cover the version-control policy and the domain skills.
For RTL, the evaluator Ep may include compilation, simulation, coverage extraction, and assertion or testbench checks. In other domains, that same slot could hold unit tests, theorem provers, profilers, or synthesis tools. Problems are therefore defined over git worktrees, not over a fixed repository type.
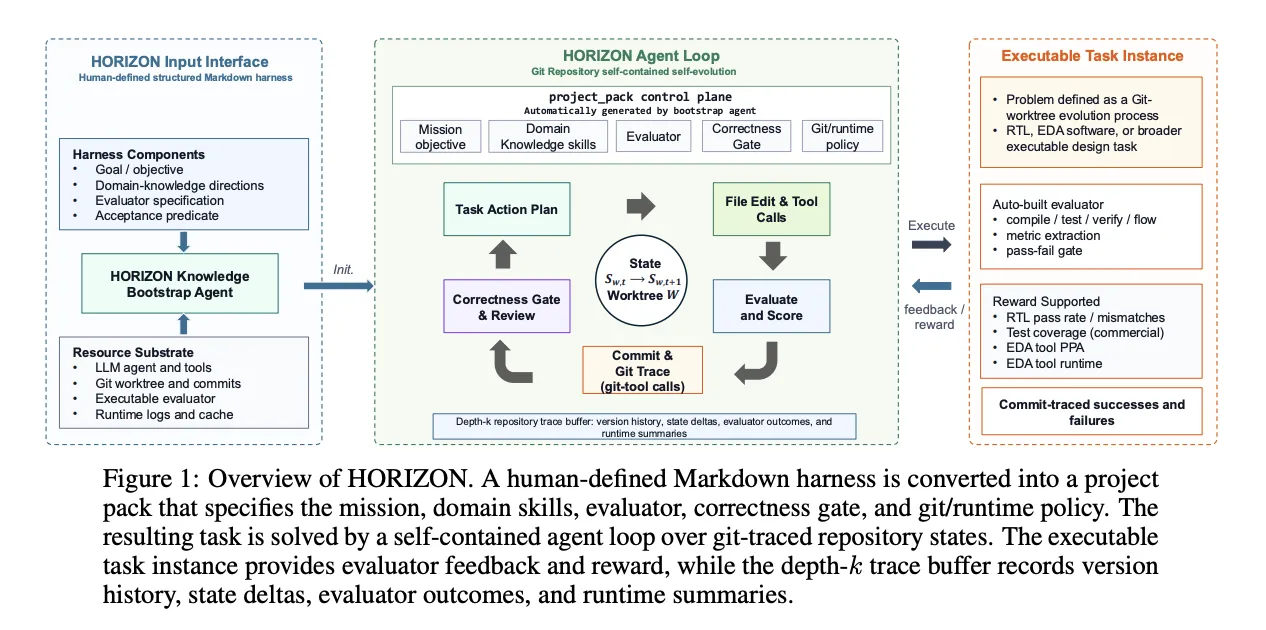
How the Repository-Level Loop Works
After bootstrap, the loop runs without further human input. Each cycle plans a target, edits the worktree, invokes tools, and runs the evaluator. The acceptance predicate then decides one thing: commit the new version, or log the failure.
Git is the substrate here, not incidental bookkeeping. Diffs expose proposed state changes. Commits define accepted checkpoints. Notes attach evaluator evidence. The log recovers the full trajectory.
The loop leans on native git commands to keep tracing cheap. Staged edits are inspected with git diff –cached. Each accepted attempt becomes a git commit whose notes carry the verdict and reward. Successful commits become positive repair examples. Rejected attempts are logged as negative examples. The repository history is the experience buffer, not a separate datastore.
The research team borrow semi-Markov decision process vocabulary for one narrow purpose. It names the recorded objects, nothing more. A ‘state’ is a versioned snapshot of the repository. An “option” is one episode between two checkpoints. HORIZON does not train or update an RL policy in this work. The agent backbone stays fixed throughout a campaign.
Session reuse keeps cost down. HORIZON holds a persistent model session across iterations. The harness, project pack, and stable sources are served from the provider’s prompt cache. Newly billed tokens are then dominated by the current diff and the latest evaluator output.
Where HORIZON Sits Among Self-Evolving Systems
HORIZON extends a lineage of repository-scale self-evolution. Earlier systems evolved the software that engineers run. HORIZON instead evolves the hardware artifacts that engineers create.
All four share one principle. A candidate change is admitted only when executable evidence supports it.
Benchmark Results
The backbone is GPT-5.3, fixed for all experiments. Every result uses single-agent, hands-free mode. Campaigns ran on an AMD EPYC 9334 32-core host with 512 GB of RAM.
The evaluation spans ChipBench, RTLLM-2.0, and Verilog-Eval. It adds nine CVDP code- and verification-generation categories, CID 002 to 016. CVDP contains 783 human-authored problems across 13 task categories (Pinckney et al., 2025).
An iteration is one automated outer step. The agent edits the worktree, runs the evaluator, then commits a pass or logs a rejection. HORIZON reaches a 100% pass rate on every suite. The one residual miss is a ChipBench specification-harness defect, not an agent failure.
The aggregate first-iteration pass rate is 47.8%. Iteration-0 is not a standalone Pass@1 measurement. It is the repository state after the first agent iteration. The agent may defer debugging and repair to later iterations by design.
Convergence difficulty varies widely across categories. RTLLM-2.0 and Verilog-Eval reach 100% within two iterations. Checker generation (CID 013) starts at just 3.8%. Yet it climbs steadily to 100% by iteration 19, with almost no plateau. Code completion (CID 002) needs 82 iterations. Its long tail is the single largest token cost.
Interactive Metrics Explainer
Where the Tokens Go
Token consumption is the more informative signal once correctness saturates. The three legacy suites together use 6.0M tokens. The nine CVDP categories use 203.9M tokens, or 97.1% of the total. CID 002 alone uses 56.0M tokens.
About 91% of all tokens are cached input, which significantly lowered the API cost. The research team therefore treat token efficiency, not final pass rate, as the metric most in need of improvement.
Use Cases With Examples
The evaluated categories map directly to daily RTL work:
- RTL code completion (CID 002): convert many failing completions into passing designs.
- Natural-language spec to RTL (RTLLM-2.0, CID 003): implement a module from a written spec.
- Modification and module reuse (CID 004, CID 005): edit or adapt existing RTL under test.
- Linting and QoR improvement (CID 007): clean up code the harness flags.
- Verification generation (CID 012 to 014): produce testbench stimulus, checkers, and assertions.
- Debugging (CID 016): localize and fix functional bugs against simulator feedback.
Checker generation is a concrete example. Single-shot models struggle with it, as the low 3.8% start shows. HORIZON instead iterates against commercial-EDA simulation until the checker passes.
A Look at the Harness
The user-facing input is a Markdown harness, not code. The skeleton below illustrates the four described components.
Copy CodeCopiedUse a different Browser# HORIZON Harness: fifo_sync
## Goal / objective
Implement a synchronous FIFO. Depth 16, 8-bit data.
## Domain-knowledge directions
- Reset is synchronous, active-high.
- full and empty must never assert together.
- Follow ready-valid handshake conventions.
## Evaluator specification
- Compile with the suite's native flow.
- Run the provided simulation testbench.
- Extract functional coverage where available.
## Acceptance predicate
- Simulation passes with zero mismatches.The loop then drives the repository with plain git operations.
Copy CodeCopiedUse a different Browsergit diff --cached # inspect staged candidate edits
git commit -m "iter 7: fix full/empty overlap"
git notes add -m "pass=1 mismatches=0" # attach evaluator evidence
git log --oneline # replay the search trajectoryStrengths and Limitations
Strengths:- One protocol covers generation, completion, and repair across whole suites.
- The framework is agnostic to the underlying generator or backbone.
- Native git makes tracing and replay essentially free to maintain.
- Session reuse keeps the marginal cost of each iteration low.
- The reward-feedback interface allows over-solving or reward hacking. A pass can mean ‘satisfies the visible harness,’ not the full specification.
- These benchmarks are controlled proxies for a much broader engineering problem.
- Feedback turnaround is favorable here. PPA-oriented loops can instead take days or weeks.
- Coverage is observational, not the target. CID 012 passes at 97.9% average coverage, since the gate stops each design once it passes.
- Synthesis quality-of-results (QoR) is not optimized here; the reported reward covers pass rate, coverage, and tokens.
The research team propose a two-level protocol for future benchmarks. Expose diagnostic feedback during repair. Reserve hidden randomized tests, reference models, and formal checks for final scoring.
Key Takeaways
- HORIZON manages RTL design as repository-level code evolution over an isolated git worktree.
- A Markdown harness compiles into a project pack: evaluator, acceptance predicate, git policy, domain skills.
- It reaches a 100% pass rate on all evaluated suites; the only miss is a benchmark defect.
- About 91% of tokens are cached input, and cost concentrates in a few hard CVDP categories.
- The research team do not claim hardware design is solved; reward hacking and long-turnaround reward stay open.
Check out the Paper here. Also, feel free to follow us on Twitter and don’t forget to join our 150k+ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Need to partner with us for promoting your GitHub Repo OR Hugging Face Page OR Product Release OR Webinar etc.? Connect with us
The post NVIDIA HORIZON: A Hands-Free Agent that Evolves Git Worktrees and Hits 100% RTL Benchmark Completion appeared first on MarkTechPost.